Last week I heard the acronym NORA mentioned with regards the kind of problems that Microsoft’s algorithm could solve. NORA stands for no one real answer. Search is already pretty good at answering questions like ‘what time is it in Osaka’ or ‘what is the capital of Kazakhstan’.
In the mid-2000s NORA would have been called ‘knowledge search‘ by the people at Google, Yahoo! and Bing – who were the main search engine companies. So its not a new idea in search, despite what one might believe based on the hype around chatbot enabled search engines. ChatGPT and other related generative AI tools have been touted as possible routes to get to knowledge search.
Knowledge search
Back when I worked at Yahoo! the idea of knowledge search internally was about trying to carve out a space that useful and differentiated from Google’s approach as defined by their mission:
To organise the world’s information and make it universally accessible and useful
Our approach to search – Google
Google was rolling out services that not only searched the web. It also covered maps, the content of books including rare libraries and academic journals. It was organising the key news stories and curating which publications were seen in relation to that story. It could tell you the time elsewhere in the world and convert measures from imperial to metric.
Google’s Gmail set the standard in organising our personal information, making the email box more accessible and searchable than it had been previously. We take having a journaled hard drive for granted now, but at one time Google Desktop put a search of the files on your computer together with online services in one small search box.
Being as good as Google was just table stakes. So when I was at Yahoo! we had our own version of Google Desktop. We bought Konfabulator, that put real time data widgets on your desktop and were thinking about how to do them on the smartphone OS of the time Nokia’s Symbian S60. Konfabulator’s developer Arlo Rose went on to work on Yahoo!’s mobile experiences and Yahoo! Connected TV – a photo-smart TV system that was before the modern Apple TV apps. Tim Mayer led a project to build out an index of the web for Yahoo! as large, if not bigger than Google’s at the time. And all of these developments were just hygiene factors.
My colleagues at Yahoo! were interested in opinions or NORA; which is where the idea of knowledge search came in. Knowledge search had a number of different angles to it:
- Tagged content such as my Flickr photo library or social bookmarking provided content from consumers about a given site that could then be triangulated into trusted context, or used to train a machine learning model of what a cat looked like
- Question and answer services like Quora, Yahoo! Answers and Naver’s Jisik In Service improved search. Naver managed to parlay this into becoming the number one search engine for Korea and Koreans. Google tried to replicate this success with Knol and failed
- Reviews. Google managed to parlay reviews into improving its mobile search offering. Google acquired Zagat in 2011. This enabled Google to build a reputation for good quality local restaurant reviews. It eventually sold the business on again to another restaurant review site The Infatuation
The ChatGPT type services in search are considered to provide an alternative to human-powered services. They create NORA through machine generated content based on large data sets trawled from the web.
Energy consumption
A conventional Google internet search was claimed to consume 0.3 watt/hours of power according to Google sources who responded to the New York Times back in 2011. This was back when Google claimed that it was processing about one billion (1,000,000,000) searches per day. It accounted for just over 12 million of the 260,000,000 watt hours Google’s global data centres use per day. The rest of it comes from app downloads, maps, YouTube videos.
But we also know that the number of Google searches ramped up considerably from those 2011 publicly disclosed numbers
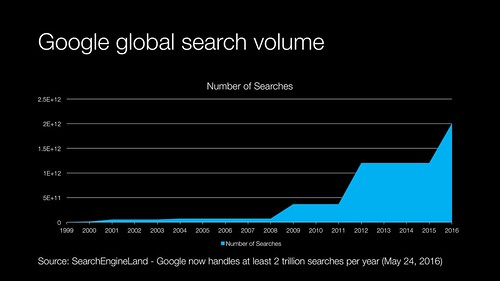
The driver for this increase was mobile search including more energy intensive Google Lens and voice activated searches thanks to Android.
Large language models (LLMs) are computationally intensive and this will result in a corresponding rise in energy consumption. That also has implications in terms of business profit margins as well as ESG related considerations.
Legal liabilities
With NORA content being created by machine learning services, it might be different to the previous generation of knowledge search services. These services were platforms, but machine learning services become publishers.
This becomes important for a few reasons
- Increased costs (while they aren’t using an army of writers, they are using a lot of computing power to generate the responses)
- Legal protections (in the US)
- Intellectual property and plagiarism issues, currently they can handle it just by taking down the content. Once they become a publisher rather than a platform things become more complicated
“no provider or user of an interactive computer service shall be treated as the publisher or speaker of any information provided by another information content provider”
Communications Decency Act of 1996.Section 230
Section 230 has been repeatedly used to regulate Facebook, Google et al in a lax manner as they haven’t been ‘publishers’, with ChatGPT this may change. The question of whether an algorithm is a creator has some precedence. Financial reporting has used machine learning to create news reports on company financial results over a number of years. Combine that with the general political antipathy towards Meta and Alphabet from both of the main US political parties and things could get interesting very fast.
It is interesting that OpenAI is putting a lot of thought around ethics in LLM, which will impact future services and they probably hope stave off regulation.
Regulated industries and liability
Given an LLM’s ability to make things up it can:
- Gives advice without pointing out health risks by creating a workout plan or a weight loss diets
- Gives bad legal advice
- Infringe regulations surrounding different industries like financial services
This is just the tip of the iceberg that NORA content powered by LLMs face.
Business model disruption
Search advertising as we know it has been the same for the past two decades. The disruption to the look and feel of search results through Bing’s chat response has a negative impact on Google’s advertising model with the search ads along the top and down the right hand side of the search engine results page. Instead you’ll end up with the ‘correct’ answer and no reason to click on the search adverts.
Currently if a non-relevant site shows up in Google. The lack of relevance is blamed on the site rather than the search engine. However an error in a machine learning created NORA response will see the search engine blamed.
Which is pretty much what happened when Google demonstrated their efforts in the area. Inaccuracies in a demonstration held in Paris cause the share price of Alphabet to decline by 7 percent in one day. Technology news site TechCrunch even went as far as to say that Google is losing control.
Microsoft probably doesn’t have a lot to lose in Bing. So integrating ChatGPT’s LLM might give them a few percentage points of search market share. Microsoft thinks that each percent gain would be worth 2 billion dollars in extra revenue.
The 2 billion number is an estimate and we don’t know how the use of NORA results generated by LLM will affect bidding on search keywords. That 2 billion might be a lot less.
Is NORA the user problem that Google and Bing’s use of LLMs are fixing?
Around about the time that Google enjoyed a massive uptake in search it also changed search to meet a mobile paradigm. Research type searches done by everyone from brand planners to recruiters and students have declined in quality to an extent that some have openly questioned is Google dead?

Boolean search no longer works, Danny Sullivan at Google admitted as much here. While Google hasn’t trumpeted the decline of Boolean search, ‘power’ users have noticed and they aren’t happy. That narrative together with the botched demo the other week reinforced each other.
Unfortunately, due to the large number of searches that don’t require Boolean strings, Google wasn’t going to go back. Instead, chat-based interfaces done right might offer an alternative for more tailored searches that would be accessible to power users and n00bs alike?
Technology paradigm shift?
At first the biggest shock that myself and others had seeing the initial reports was how Google and Microsoft could have been left in the dust of OpenAI. Building models requires a large amount of computing power to help train and run.
Microsoft had already been doing interesting things in machine learning with Cortana on Azure cloud services and Google had been doing things with TensorFlow. Amazon Web Services provides a set of machine learning tools and the infrastructure to run it on.
Alphabet subsidiary DeepMind had already explored LLM and highlighted 21 risks associated with the technology, which is probably why Google hadn’t been looking for a ChatGPT type front end to search. The risks highlighted included areas such as:
- Discrimination, Hate speech and Exclusion although there is research to indicate that there might be solutions to this problem
- Information Hazards – there has already been a case study on how an LLM can be influenced to display a socially conservative perspective.
- Misinformation Harms – researchers claimed that LLMs were “prone to hallucinating” (liable to just make stuff up)
- Malicious Uses
- Human-Computer Interaction Harms
- Environmental and Socioeconomic harms
Stories that have appeared about ChatGPT and Bing’s implementation of it seem to validate the DeepMind discussion paper on LLMs.
The Microsoft question of why they partnered with ChatGPT rather than rolling out their own product is more interesting. Stephen Wolframs in-depth explanation of how ChatGPT works is worth a read (and a couple of re-reads to actually understand it). Microsoft’s efforts in probabilistic machine learning looks very similar in nature to ChatGPT. As far back as 1996, then CEO Bill Gates was publicly talking about how Microsoft’s expertise in Bayesian networks as a competitive advantage against rivals. Microsoft relied on research and the Bayesian network model put forward by Judea Pearl which he describes in his book Heuristics.
Given the resources and head start that Microsoft had, why were they not further along and instead faced being disrupted by OpenAI? Having worked in the past with Microsoft as a client, I know they won’t buy into anything that they can build cheaper. That raises bigger questions about Microsoft’s operation over the past quarter of a century and its wider innovation story to date.
Flash in the pan
At times the technology sector looks more like a fashion industry driven by fads more than anything else. A case in point being last years focus on the metaverse. The resulting hike in interest rates has seen investment drop in the field. Businesses like Microsoft and Meta have shut down a lot of their efforts, or have scaled back. It is analogous to the numerous ‘AI winters‘ that have happened over the past 50 years as well.
Bing’s implementation of LLM is already garnering criticism from the likes of the New York Times. This new form of search may end up being a flash-in-the-pan like Clubhouse. The latent demand for NORA in search will still be there, but LLM might not be the panacea to solve it. Consumers may continue to rely on Reddit and question-and-answer platforms like Quora as an imperfect solution in the meantime.
In summary….
- NORA content generated by LLMs represent a new way to solve a long known about challenge in online search
- NORA as a concept was previously called knowledge search
- NORA content competes with: social media including Reddit, specialist review sites including Yelp or OpenRice and question and answer services including Quora
- ChatGPT and similar services affect human perceptions of search and the experience makes them more critical of the search engine response is not of an acceptable standard
- LLMs represent a number of challenges that large technology companies have discussed publicly, but were still attractive for some reason
- ChatGPT shows up the the decades of research that Google, Microsoft and Amazon have put into machine learning, this will negatively affect investors attitudes to these companies and merits a more critical nuanced examination of ‘innovation’. These large companies seem to be struggling to put applied innovation into practice. Microsoft buying into ChatGPT is essentially an admission of failure in its own efforts over at least 3 decades. Even ChatGPT’s deeply flawed product is considered to be better than nothing at all by these large technology companies
- Use of ChatGPT like services expose Google and Bing to business risks that are legal and regulatory in nature. It could even result in loss of life
- ChatGPT’s rise has surfaced deep seated concerns amongst technologists, early adopters, power users and investors about Google’s ability to execute on innovation successfully now (and in the future). Google’s search product has been weakened over time by its focus on mobile search dominance. Alphabet as a whole is no longer seen as a ‘leader’
- LLMs, if successful would disrupt the online advertising business model around search engine marketing
- ChatGPT and its underlying technology do not represent a paradigm shift
- There is evidence to suggest that ChatGPT and other LLM powered chat search interfaces could turn out to be a fad rather than a future trend. The service as implemented has underwhelmed